
Workbook 2
Die Anwendung von großen Sprachmodellen
Erkunde die Fähigkeiten sowie potenzielle und vorhandene industrielle Anwendungen heutiger großer Sprachmodelle
2.1 Introduction
Development in artificial intelligence gained remarkable results and improvements in recent years. Based on new deep learning methods, bigger model architectures, more available data and computational resources, researchers and engineers developed fascinating AI models able to generate texts hardly distinguishable from human-written texts, photo-realistic images, artificial video and music sequences, and even source code as the core description of software. We call these models generative AI models as those models are able to artificially generate data based on examples or even textual descriptions.
As an example, let us consider the large language model called GPT-3 that was published by the startup OpenAI in June 2020. Since then, GPT-3 has indeed changed the public opinion on what AI is able to do. GPT-3 can produce texts and even code, when given a brief prompt with instructions and descriptions of the particular task the LLM should perform. Based on the respective task, the results are then generated answers or responses given a question, or the completion of an article, essay or even joke given an initial description. And although those results are far from being perfect, people got fascinated a lot and are since then wondering what will come next. One thing became certain, the size of models matters.

Since then the development of large language models became a race regarding model size and number of developed and released models. Over the past few years, the size of large language models has increased by a factor of 10 every year. It seems to be beginning to resemble another Moore’s Law . ( 1 can give you a direct impression of how LLMs scaled in past years). Along with this tremendous growth of the model sizes, the race and development also result in more and more releases of AI models globally. So far only in 2022, there have been 42 different LLMs released with impressive scaling of their training dataset even if we only focus on western countries. And in 2023 GPT-4 and more are on their way. For a more detailed overview of recently published LLMs, LifeArchitect.ai has shared a very detailed Summary of current models .
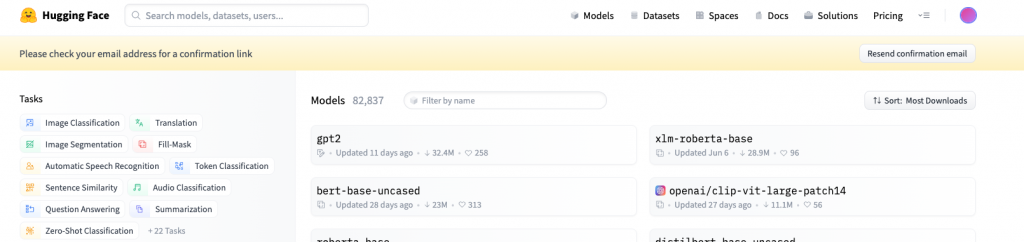
When we are curious about the usage of LLMs, then we could take a look at how many fine tuning models have been developed. And to answer this question, then one of the most famous open source platforms, Hugging Face Hub can show us the reality. Even within this single platform, over 60K models, 6K datasets, and 6K demos are open sourced in which people can easily collaborate in their machine learning workflows. And among these models, we can tell that LLM is currently definitely one of the most popular kinds of AI models. Currently 2 out of the top 3 most downloaded models are LLM, GPT-2 with 32.4 Mio. downloads and bert-base-uncased with 23 Mio. downloads.
Since then the development of large language models became a race regarding model size and number of developed and released models. Over the past few years, the size of large language models has increased by a factor of 10 every year. It seems to be beginning to resemble another Moore’s Law . ( 1 can give you a direct impression of how LLMs scaled in past years). Along with this tremendous growth of the model sizes, the race and development also result in more and more releases of AI models globally. So far only in 2022, there have been 42 different LLMs released with impressive scaling of their training dataset even if we only focus on western countries. And in 2023 GPT-4 and more are on their way. For a more detailed overview of recently published LLMs, LifeArchitect.ai has shared a very detailed Summary of current models .
When we are curious about the usage of LLMs, then we could take a look at how many fine tuning models have been developed. And to answer this question, then one of the most famous open source platforms, Hugging Face Hub can show us the reality. Even within this single platform, over 60K models, 6K datasets, and 6K demos are open sourced in which people can easily collaborate in their machine learning workflows. And among these models, we can tell that LLM is currently definitely one of the most popular kinds of AI models. Currently 2 out of the top 3 most downloaded models are LLM, GPT-2 with 32.4 Mio. downloads and bert-base-uncased with 23 Mio. downloads.
2.2 Considering General Tasks of LLMs
We would like to warm you up before deep diving into the industrial use cases with several most important and common tasks of LLMs. They are the foundation and key success factors for most of the industrial use cases. We collected several open source examples from OpenAI, there are of course many more successful and interesting research companies and institutes also doing researches on LLMs, we selected OpenAI because it’s bride covered research topics in LLMs and also their playground provides rich examples you can get a very direct impression with easy access, thus we strongly recommend you to try it out ! Also worth to mention is the collaboration between OpenAI and Microsoft with a strategy based on Azure Cloud (i.e. AI models as a platform) also made them stay in one of the best positions of industrialization.
-
 TEXT GENERATION
TEXT GENERATIONText generation, formally referred to as natural language generation, aims to produce reasonable and readable text in human language based on input data, e.g. a sequence and keywords. It’s also the foundation of the question and answering system (i.e. response generation, answer generation).
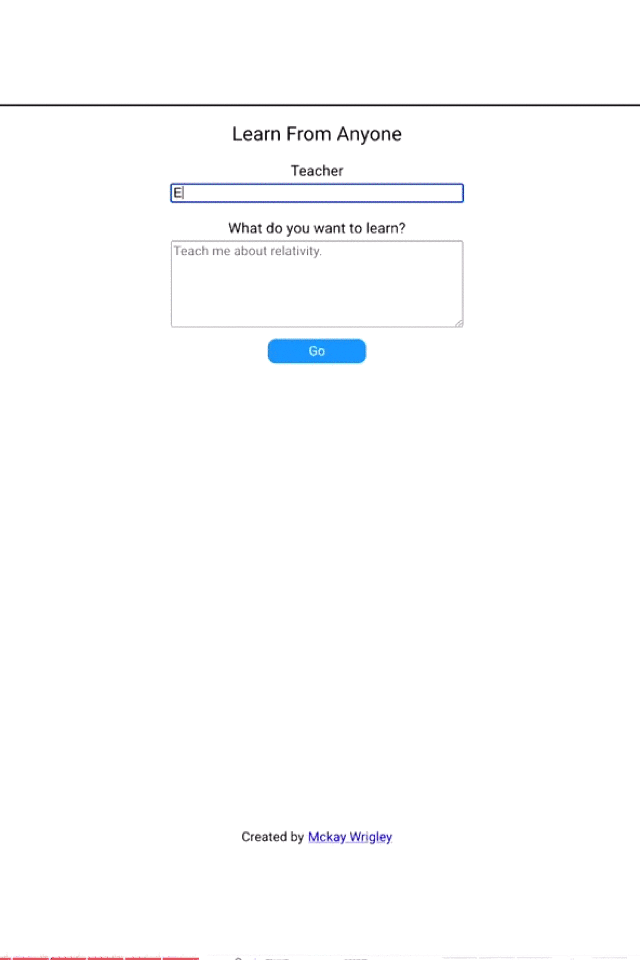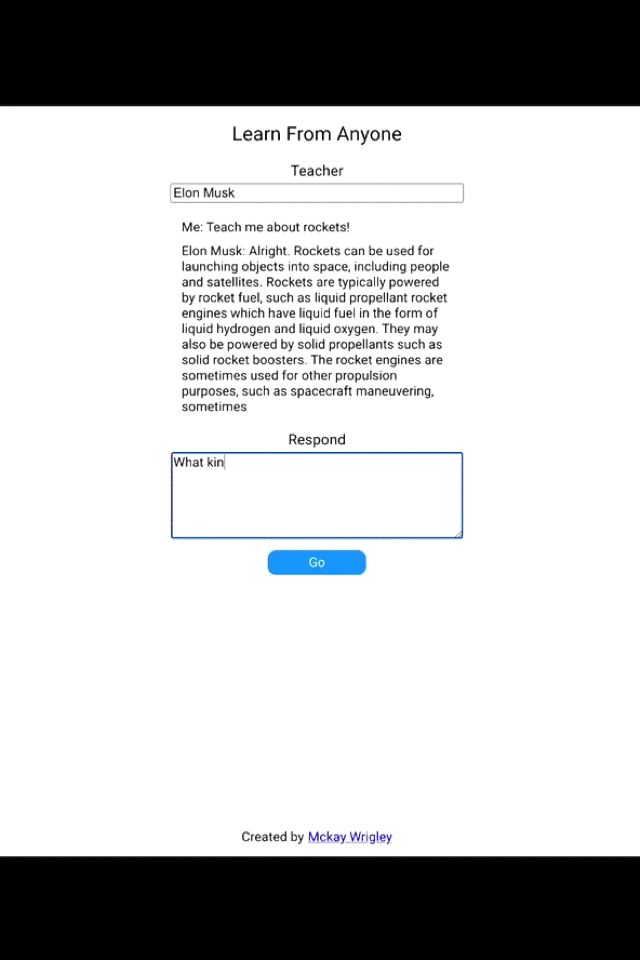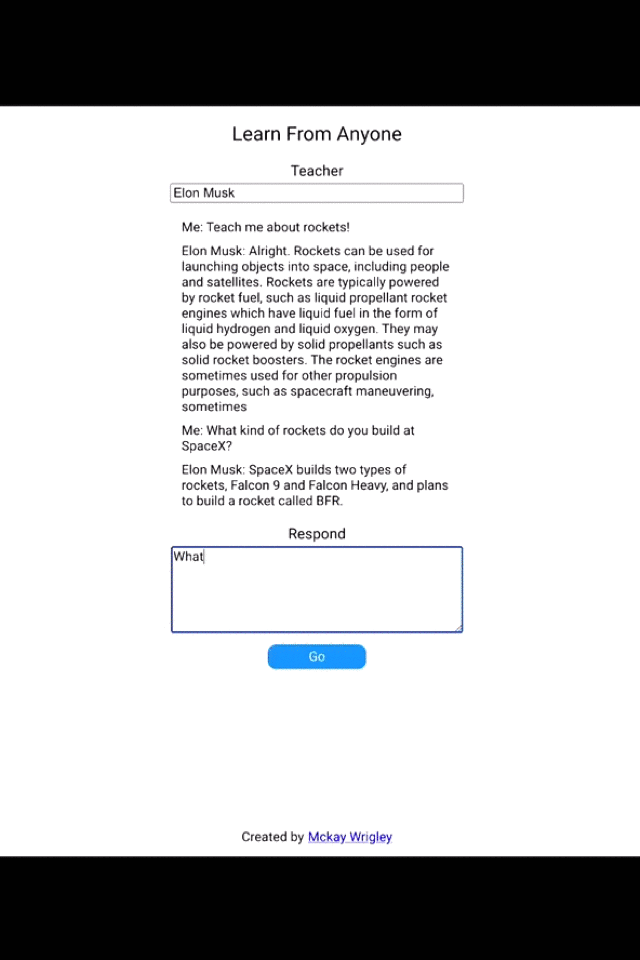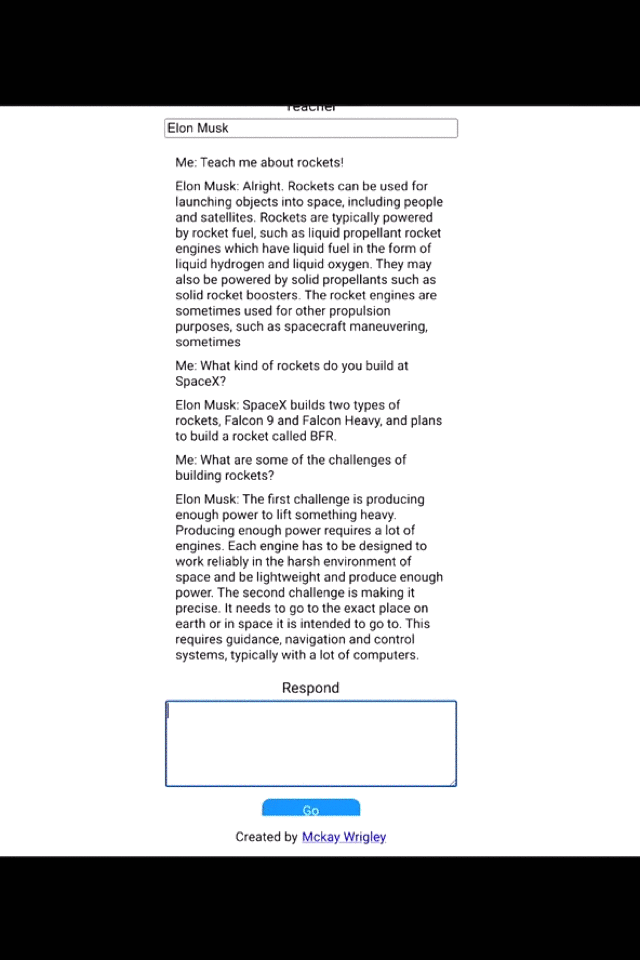
The automated generation and completion of text on sentence or paragraph level is an important Natural Language Processing (NLP) task and can be widely used in many industries with shared use cases for generating articles, news, marketing slogans, social posts, protocol, and all kinds of product descriptions. This list can be extended for many more text types, therefore, text generation is an important task across industries and use cases. We recommend you to get an impression of the state of the art technology by trying it out yourself, the Generation API , it is one of the most powerful and popular software offerings of OpenAI , based on GPT-3. It can generate all kinds of content, the popular example which you can test out below is to generate new ideas , business plans, marketing slogans or even support your interview questions based on your prompt (see explanation in workbook 1). Below is an example to get you motivated.
Taking text generation as a core NLP task, many startups and software have been initialized and generate a lot of usages. For example, CopyAI is well-known as a GPT-3 powered tool to automate creativity tools and generate marketing copies within a short period of time efficiently. Businesses can use this AI model for digital ad copy, social media content, website copy, eCommerce copy, blog content, and sales copy. And Snazzy AI is known for providing the simplest way to create content with GPT-3. Multiple services include creating landing pages, copywriting, Google Ads, and many more with just three clicks.
-
 IMAGE GENERATION
IMAGE GENERATIONNext to text, the ability to generate artificial images based on pre-selected image examples or textual description is another important key application of AI models in general, and of latest large language models specifically. It’s also known as image synthesis.
Various different AI model architectures (i.e. deep learning methods) have been published in recent years, and are also known as generative AI models. Recently, LLM and diffusion models have arisen with a significant improvement of the ability to generate up to photo-realistic images with a broad range of content, style and variation based on a solely text-based prompt. In 2022, LLM models such as the DALL.E 2 of OpenAI, Stable Diffusion of stability.ai or Luminous by aleph alpha became very popular for this task.
DALL.E 2 is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions, using a dataset of text–image pairs. OpenAI has released a first text to image model called DALL.E in 2021 and it has got a lot of attention in 2022 with its 2nd generation. The performance and robustness of DALL.E 2 also made it possible for a wide range of use. Microsoft is bringing DALL.E 2 not only into its cloud AI services, but also directly integrating it to its software products and ecosystems, such as Teams APP Platform, new Designer platform.
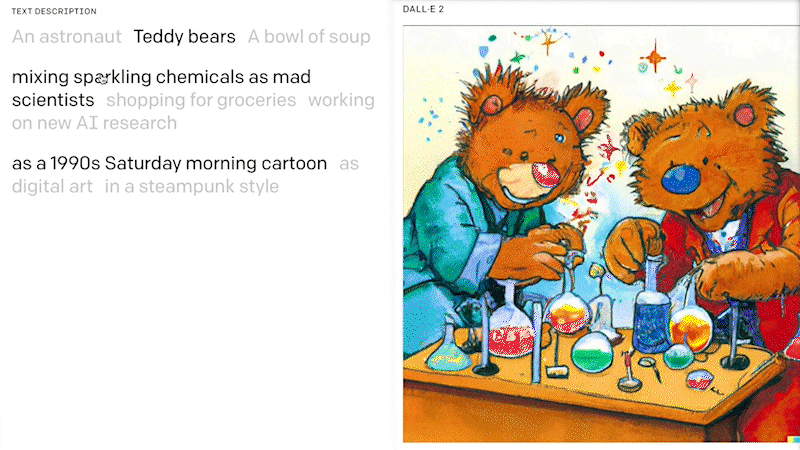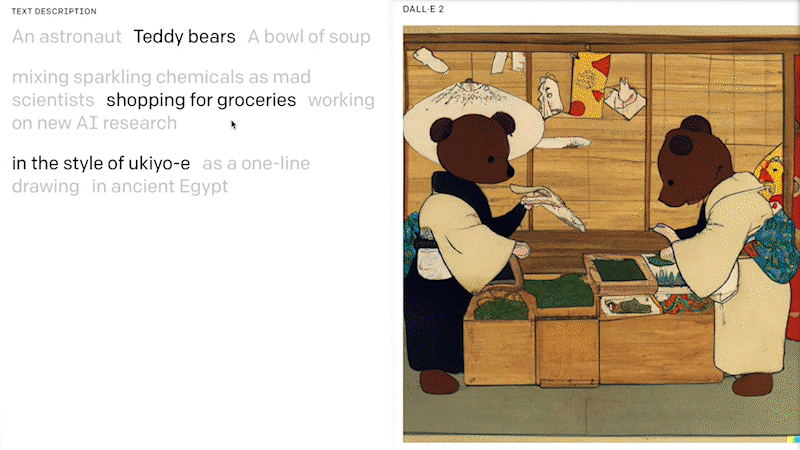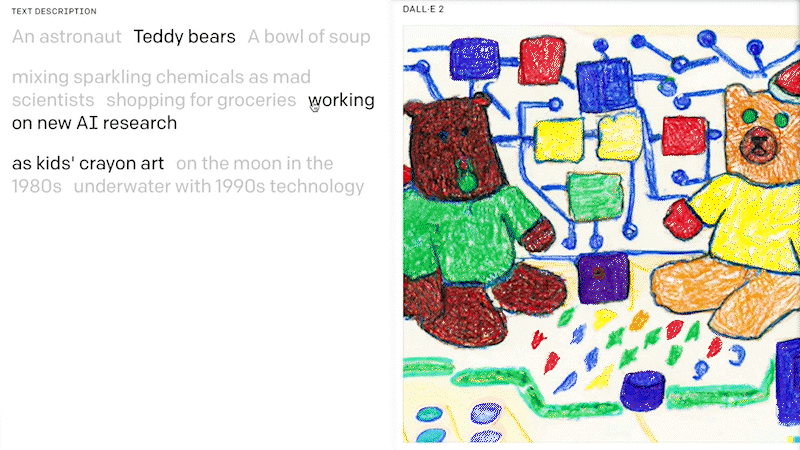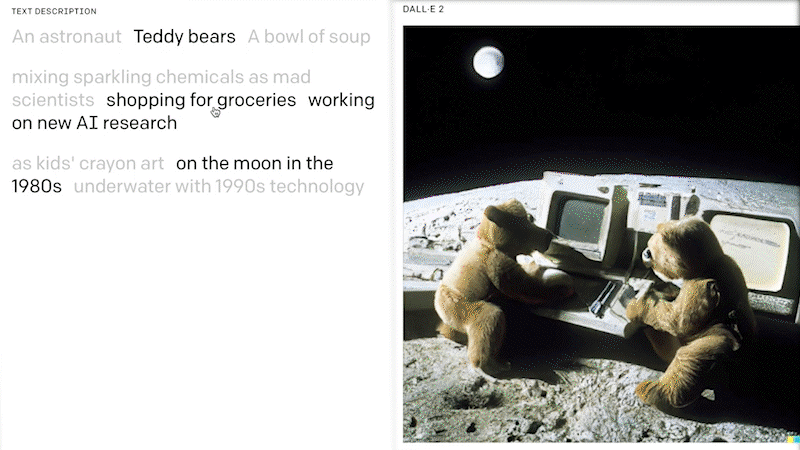
You can also have a free test here , which is an open source playground to generate images from any text prompt using DALL-E Mini and based on OpenAI’s DALL-E. And luckily in this area, there’s also something happening closer to us in Germany, which the main research work has been done in LMU, Munich, e.g. the announcement of the stable diffusion model from stability.ai . Stable Diffusion is a text-to-image model similar to DELL.E that will empower billions of people to create stunning art within seconds.
Different then DALL.E and Diffusion Models, Luminous from aleph-alpha focusing in a special and interesting direction. Luminous has a basic and extended model, both are Multilingual models trained on English, German, French, Spanish and Italian. Luminous-base can read, explain and generate text from existing images, such as context question and answering based on given images; or to generate creative artwork titles based on images; or analyze and summarize based on image comparison. You can test them out in the aleph-alpha playground .
With this significant progress of LLM models for image generation in 2022, we observe a shift in the way we consider AI-based content generation at all. Coming from text generation only, various AI models now focus multi-modal generation of video, audio or even music. As a result, large language models have founded a new hype of Artificial General Intelligence (AGI) in research, tech companies as well as industry around the globe.
-
 CODE GENERATION
CODE GENERATIONCode generation could mean translating natural language to code, or translating code between different programming languages. Since the LLM became capable of generating code, the Low code / No code tools has always been one of the hot topics in AI use cases and among all the developers. One of the major questions everybody has in mind is, how big could the market of AI software engineering grow, if it will really be able to replace some of the software developer roles?
Well the question shouldn’t be answered by us, we would like to encourage you to take a look at the various examples of CodeX which you can use your human language (see an example below and read more ) or if you are developers, definitely try out first code generation product from Microsoft Copilot , then you will have your own answer 🙂
Also some start up companies showed the possibilities. One example is Debuild.co is a top GPT-3 driven app for developing website apps rapidly and effectively. With just one click, SQL code can be generated and an interface can be put together visually. It makes use of this AI model to develop an autonomous software writing system that is on par with the best developers.
-
 MACHINE TRANSLATION
MACHINE TRANSLATIONMachine translation has a very long history starting from 1954 with the first rule-based solution of IBM and is a fundamental task of NLP and AI in general. A major milestone in the history of machine translation was the introduction of Deep Learning starting in 2016. It was a paradigm shift by outperforming statistical machine translation ( SMT ) which was the common approach at this time. Today, machine translation solutions are only using deep learning and, therefore, we call it neural machine translation ( NMT ) .
One of the companies that took the chance is German MT specialist DeepL . Its product is currently even becoming one of the most popular websites globally with more than a billion of people using their services. Because MT is very easy and necessary to integrate into different end customers‘ products, specially for international markets.
Nowadays, we observe more specific large language models that are also being integrated into NMT solutions. One important reason for this is to improve the translation quality of so-called low resource languages by the use of LLMs, mostly even multi-lingual LLMs. Low resource languages can be understood as less studied, resource scarce, less computerized, less privileged, less commonly taught, or low density, among other denominations languages, in the MT topic specially for NMT, those human languages with low amounts of digitally available corpora data (translation pairs) to train NMT models, are all low resource languages. For example, Korean, Vietnamese and many other languages in Asia, Africa. In Europe, except English, German, French, Spanish, most other languages are also from NMT perspective as low resource languages.

Various technology companies do heavily invest in research on different LLM architectures and methods optimized for machine translation.
For instance Amazon Web Services (AWS) has recently released the Bloom of Alexa Teacher Model which showed state-of-the-art performance on machine translation focusing on in-context learning. These results are important for AWS as it will improve key offerings such as its own machine translation product AWS Translate and its virtual assistant Alexa.
And a traditional research company like OpenAI provides its MT services with its Chinchilla model which focuses more on optimal model size and number of tokens under a given compute budget. Open source projects such as BLOOM are trained to continue text from a prompt on vast amounts of text data using industrial-scale computational resources. As such, it is able to output coherent text in 46 languages and 13 programming languages that is hardly distinguishable from text written by humans. It is not only powerful but also more focusing on collaborative and supporting future AI applications such as chatbots for the open source communities and try to bring more human value such as avoid discrimination and bias.
-
 TEXT SUMMARIZATION
TEXT SUMMARIZATIONText summarization is aiming to convert a large body of text to a few sentences without losing the key themes of the text. Very often we need to grasp the context of text and rephrase it in different ways. This can be used widely from news and
summarization, reports and briefings preparation, even
. In digital times, information is exploding every second, people always want to get the most important information in even a few seconds. Therefore text summarization has drawn attention to researchers as well as tech companies for a long time with many
And this is a typical task where it is hard to agree on a best method, since the performance highly depends on the user scenarios. meeting notes generate mindmap from text documents different approaches.

Here our Open GPT-X partner aleph-alpha also provided their Luminous-extended Model, which is a Multilingual model trained on English, German, French, Spanish and Italian for text and document summarization. If you know any of the languages above, it would be fun to test it out!
-
 SPEECH RECOGNITION
SPEECH RECOGNITIONSpeech recognition, also known as automatic speech recognition (ASR) or speech-to-text, is a capability which enables a program to process human speech into a written format . It’s commonly confused with voice recognition, the simplest explanation of the differences between speech and voice recognition is, speech recognition translates anyone’s voice; voice recognition understands a specific user’s voice. Speech recognition enabled all hands-free user experience, Siri, Alexa, Google Assistant. All kinds of voice assistants are already a must-have for smart devices from mobile phones to smart speakers and even in cars and robots. Except for complicated applications such as voice assistants, speech recognition is also widely used in use cases such as call centers or dictation related applications, e.g. in healthcare supporting doctors and manufacturings. But normally, models behind those famous products are block boxes for the public, Alexa or Google; they both provide their voice assistant as a development platform, to encourage worldwide developers to help build 3rd party functions into their voice assistant, such as Alexa skills and Google Actions , which your product also becomes part of their big ecosystem. However, in the past, not only as users but also for researchers, ASR systems have not really achieved human level performance. Last month openAI released their result to try to overcome this challenge, a new ASR model called Whisper that shows human levels of accuracy and robustness outperforming both supervised and unsupervised models in the space, you can now give a test here .
2.3 Considering Selected Industries: Success Story & Use Cases
One of the big challenges of applying LLMs is domain adoption, for each industry there’s so many special requirements and processes and vocabularies. In the remaining part of this workbook let’s deep dive into some success stories from different industries and some real use cases where LLM has already been used and generated an impact or even become a game changing factor.
2.3 Conclution
This workbook should have helped you to answer the question we start with, about what kind of potential use cases are feasible and worth implementing using LLMs in AI use cases in enterprises across industries.
We predict that LLMs will have a game-changing impact among many products and processes in all kinds of industries. In particular, it will be a future core technology in the interaction between humans and machines or systems. However, we also believe that the rise of LLMs has just started and industrialization is still challenging in manifold directions. Much more needs to be explored better today than tomorrow in order to exploit this significant AI technology and generate added value in industry.
With the tremendous speed LLMs are growing, it might result in decreasing returns, increased expense, increased complexity, and rising risks. That is what we are going to deep dive into with the workbook 3.